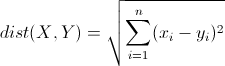从零训练大模型系列 · Day 4 — 从GQA到MLA:KV Cache还能再压缩吗?DeepSeek团队用低秩压缩将KV Cache缩小到1/6,质量几乎不损失。
RoPE旋转位置编码与GQA分组注意力
从零训练大模型系列 · Day 3 — Transformer的"失忆症":为什么需要位置编码?RoPE如何用旋转矩阵编码位置,GQA如何平衡效率与质量。
Agent的未来:2026之后会怎样
Agent不会取代人,但会取代不用Agent的人。Agent OS、Agent经济学和开放问题。
个人AI Agent实践:用OpenClaw打造你的私人助手
用OpenClaw搭建个人AI助手的完整实践:股票监控、飞书集成、代码开发。
Agent落地实战:从Demo到Production的鸿沟
90%的Agent项目死在Demo阶段。延迟、成本、可靠性——生产化的五大挑战。
Agent安全与护栏:放权但不失控
Agent安全的核心矛盾:自主性越高,可控性越低。五层安全架构设计。
多Agent编排:让一群Agent协同干活
单Agent有能力上限。串行、并行、层级、协商——四种编排模式的取舍。
Coding Agent:AI写代码的现在与未来
从代码补全到全栈开发。Cursor、Claude Code、Devin三种范式的深度对比。
Agent框架横评:LangGraph vs CrewAI vs AutoGen
2026年三大Agent框架的全面对比:LangGraph精确控制,CrewAI上手最快,AutoGen对话模式最灵活。
Agent规划与推理:思维链的力量
Chain-of-Thought让模型"想一步说一步"。从CoT到Tree of Thoughts再到ReAct,推理能力是Agent的核心竞争力。
Agent记忆系统:如何让AI不再失忆
没有记忆的Agent就像金鱼——每次对话都是全新的开始。三种记忆类型和六大框架对比。
A2A协议:Agent之间怎么对话
MCP管工具,A2A管Agent间通信。Google发起的A2A协议正在成为多Agent协作的标准。
MCP协议:Agent工具调用的USB标准
MCP(Model Context Protocol)解决了Agent工具接入的N×M问题,让它变成N+M。月下载量9700万,所有主流AI厂商已采用。
Tool Use:Agent的手和脚
LLM的知识有截止日期,算数不靠谱,不能访问文件系统。工具使用让Agent从"只会说"变成"能做事"。
Agent架构全景:一张图看懂Agent系统设计
Agent的核心架构由四个模块组成:LLM大脑、规划引擎、记忆系统、工具集。理解这四个模块的协作方式,就理解了Agent的本质。
什么是AI Agent:从聊天机器人到自主智能体
AI Agent不是聊天机器人。聊天机器人是"你问我答",Agent是"你说目标,我去完成"。
在腾讯的三年
一些认知
- 产品为王,如果说paper是research成果到展现,那产品就是你的标签和态度
- 用户为先,一个产品首先要有用户,定义清楚你的用户群体比什么都重要
- 细节很重要,在腾讯成功的产品中,所有老板都非常抠细节,并且是产品的资深用户
- 实施也是一种思考,如果想不太清楚的时候,大概率认知没到,可以先做做看,这个过程也是提升认知的过程
- 如果永远在想,而不去做,认知大概率是很浅的,只有真正去做了,才能深入的思考
- 认知决定了你的上限,人生需要去刷新认知,不然再努力也是原地踏步
- 人的成就的上限由两部分组成,(能力*network),在初级阶段,你的能力很重要,越到后面你的network越重要,因为这时候和你竞争的人能力不比你差,甚至大部分比你好
- 解决问题的最好方式是不断
增长,因为可能到某个阶段这就不是个问题了 - 想想未来的自己是怎么样的,再规划现在,以终为始
- 管理的第一性原理是要提升效率
- 要用愿景来驱动团队,而不是利益,因为终会因为利益而散
一些预测
- 未来是大模型的时代,如果把大模型比作IOS,agent就是其上繁荣的app生态
- toC的产品才是创业的未来,toB小公司耗不起,随便拖个帐期,你就垮了
- 未来信息密度会极大提升,当前基于推荐的模式,信息密度很低
我对大模型的认知
背景
- 2017.06 transformer模型架构论文发布
- 2018.06 gpt-1模型发布,参数量1.17亿
- 2019.02 gpt-2模型发布,参数量15亿,decoder-only的模型通过prompt解决非常多task,泛化能力强
- 2020.05 gpt-3模型发布,参数量1750亿,大力出奇迹,提出zero-shot,few-shot概念
- 2022.03 instruct-gpt, 参数量1750亿+RLHF,基于RLHF对齐人类偏好
- 2023.03 gpt-4发布,多模态,参数量预估万亿规模
- 2022.11 chatgpt横空出世,让我们感觉到agi真的要来了
当前各类AI+应用如雨后春笋般出现,AI+Law,AI+Data,AI+Market,AI+Assistant,AI+Math,很多人都觉得大模型是人类历史上另外一个iphone时刻,因为在其上可以用新的逻辑构建非常多应用,重塑当前的生态,连openai都觉得未来重点发展方向是agent,如最近出现的code-interpreter
什么是Agent,简单点说就是基于大模型的能力,完成特定任务的智能体,可以辅助人类解决一类问题,比如个人助理,帮你订机票,帮你订酒店等等

它主要包含几个部分tools, planning, memory, action;
- tools包含一系列的工具,比如搜索,日历,计算器,可以获取外部数据或者能力,因为这些能力通常是大模型不擅长的计算
- planning用于规划问题解决路径,通过大模型的理解能力和判断,规划用户的问题需要哪些tool来进行解决,比如用户想看些时政新闻,此时就会用到搜索引擎来进行搜索,然后整理成结构化数据展示
- memory用于记录历史步骤结果,以及用户的上下文,方便快速准确的识别用户意图
- action就是具体操作了,使用相应工具执行即可
- 当然planning的模块也包含很多设计内容,如何做反思,如何实现COT,如何拆解任务,是比较核心的模块
几点预判
- 未来所有与人交互的产品,都会变成自然语言的模式,因为这是最符合人类习惯,而大模型恰恰能做到这件事情
- 做底层大模型的公司不会太多,因为这是一个零和游戏,强者更强,反而做上层应用,toB,toC都大有前景,这里面有非常多细分的机会
- 可遇见的未来,所有产品都会被重塑,这反而是创业者的机会,因为大厂的认知现在也是初级阶段,创业者的优势是可以更快学习,适应,调整,更新
- 硬件上会有很多改变,UI的交互不是必须了,语音的能力会加强,输入法会成为历史
- 不需要太多APP了,很多基础能力互联网已经建设好,比如物流,外卖,电商,最后只需要一个Assistant
- 必须要重新学习,用新的思路来做事,以前觉得不可能的事情,现在可以做了,比如电子宠物,比真实的宠物更体贴,更自愈
~ 先说到这儿,必须要抓紧行动了
reference
- https://lilianweng.github.io/posts/2023-06-23-agent/
- https://medium.com/@gerardo.pdm/karpathy-the-potential-and-challenges-of-ai-agents-f53c55734050
- https://mp.weixin.qq.com/s/kA7FBZsT6SIvwIkRwFS-xw
- https://openai.com/research/instruction-following
- https://www.zhihu.com/question/570431477
- transformers: https://arxiv.org/pdf/1706.03762.pdf
- gpt1: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
- gpt2: https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
- gpt3: https://arxiv.org/pdf/2005.14165.pdf
- instructgpt: https://openai.com/research/instruction-following
- https://www.wolframalpha.com/input?i=exp%28x%29+from+0+to+1
- https://zhuanlan.zhihu.com/p/350017443
我眼中如何设计一个高可用系统
系统定位
一个系统明确之初,就应该定义它设计的目标,比如现有的很多大型电商系统,可用性是它设计的目标,全年要达到5个9,而很多银行系统要求很强的事务性,那强一致就是其设计目标,保证不能错;还有一些系统需要很低的延迟等;定义好我们系统的目标后,围绕这些东西可以有很多设计理念可以运用;
高可用系统
高可用系统设计上,首先定义好我们可用率的目标,比如是99.999%,表示全量最多不可用5分钟,有了指标后,我们就要拆分下如何如何达到这个目标,因为大部分系统肯定不能自己闭环,你要依赖外部服务,db,mq等;
- 强依赖(典型的后端的db,或者不可或缺的外部服务)
- 弱依赖(忍受容错,可以被降级掉)
整体服务的可用率就可以计算出来了,假设强依赖之间是相互独立的
$$
self * \prod_{dependencies}availability = 0.9999 * \prod_{dependencies} 0.9999 = 0.9997
$$
可以看出要达到最终的目标,我们需要提升自己,或者强依赖;还有一些情况是当我们不知道对方的SLA时,如何预估这个值来帮助我们设计系统,此时会用到两个指标来预估;
- Mean Time Between Failure (MTBF)
- Mean Time to Recover (MTTR)
$$
Availability Estimate = MTBF / (MTBF + MTTR)
$$
比如MTBF=150days,MTTR=1hour,我们可以预估一个可用率是99.97%,有了以上数据支撑后,需要技术上做一些事情来支撑,可用率的提升,简单总结为以下几点:容量管理
我们需要很清楚自己的系统,知道他在不同资源下的水位,如何设计系统限流等网络管理
你需要清楚自己服务的部署情况,是否会有跨机房的通信,网络延迟是怎样的,是否会导致堆积,如何处理Dos,如何做Load Balance,网络的FO等服务管理
将自身服务按照有状态和无状态进行拆分,因为你的业务特点,可能会面临每时每刻的峰值变换,要能方便的scale-outIsolation
有了独立的Replica之后,我们可以显著的提升可用率,它的计算模式变为了:
$$
self * \prod_{dependencies}not/availability = 0.9999 * \prod_{dependencies} 0.001 = 0.9997
$$level0:我们需要互相独立的available zone来提供服务,方便基础设施出现问题后进行切换level1:关键性的模块支持副本,提升这些模块的可用率,避免一些单点问题容灾管理
设计的目标是出现故障后,如何缩短恢复的时间,梳理业务的预案,出现问题后available zone的切换方案,关键模块的切换方案,或者能不能做到自动化的FO
;梳理主链路,一些弱依赖出现问题能否直接降级掉,减低风险;容灾也需要经常测试,因为不同场景的切换,可能导致流量超过某个zone的承载极限,最好能支持快速的auto-scaling;变更管理
系统出现问题的情况很多都是由于变更(部署,热变更)等,所以我们需要遵循一些变更的best practice:灰度发布,小批量多次进行发布,减少影响范围蓝绿发布,整个发布分成两个部分,当一个部分出现问题,可以FO到另外部分,然后快速回滚,进行恢复功能开关,新功能上线的时候默认把开关关闭,少量打开确认无问题后,才全量放开测试,包括代码部分的单测,集成测试;上线后的灰度测试等;测试需要覆盖正常和异常的情况监控&报警
我们需要对系统有深入且实时的了解,以便做出正确的应对
Wonderful tour in alibaba
背景
即将从阿里毕业了,因为各种各样的原因,选择了离开;很感谢这接近三年的经历,忙碌而充实;在这样的环境中学到了很多,如果用
两个字总结是感恩,感恩同事(不方便写名字了。。。),感恩这里的平台,如果你也准备去阿里,我想讲讲你可能要关注的一些事情!
我在阿里学到的一些事
- 要有会折腾的心态,即使开始看起来不怎么靠谱,路是越走越顺的
- 学会沟通很重要,能快速提升你的认知,人类有了语言以后,才建立起了统治地位
- 要用善意的眼光去看人看事,这样干起来才更有动力
- 千里马常有,而伯乐不常有,一个适合你的团队至关重要
- 要有空杯的心态,这很重要,其他能力都可以快速补齐
- 要善于使用平台,但也要认识到提升个人能力才是最重要的,想想离开平台你还有些什么
- 沟通最重要的是能正确的传递信息,所以你是要有所准备的,补齐一些认知误差,才能提升沟通效率
- 要学会在阿里生存,你就要有自己的闪光点,如何打造自己的名片,很关键
- 人终有一死,既然终点都一样,更应该看重的是过程
- writing as thinking,很多事情想不清楚可以写下来,这一过程你会慢下来,渐渐就清晰了
- 人在波澜不惊中是不会成长的,用阿里土话讲,逃离自己的舒适区
- 人生不会有倒车的机会,所以你需要向前看,只要朝着目标,只是路程远近的问题
- 站在未来的视角看现在的行为,多少是在主航道上的,keep going
未来
- 未来是不确定的,唯一不变的是,我应该会持续不断的折腾😁
什么是马拉车(manacher's)算法
背景
在计算机世界里,有一类问题叫寻找回文子串,英文叫Palindrome,这个问题在很长一段时间,人们都没找到比较高效的算法
,时间复杂度都在O(n^2),下面来看看什么是回问字符串:
可以看到整个字符串是对称的,将sub反转过来还是等于它自身,字符串的part0和part1是对称的,基于这个特点,可以写出
一个O(n^2)的算法;
Intuition
直接比较前后部分,但是要判断奇偶的情况
1 | def findPalindromeNum(s:str)->int: |
这个算法有两层循环,外层是O(n),内层最坏情况也是O(n),所以整个算法复杂度是O(n^2),里面一个很大的问题,我们进行了很多
重复的比较,这时候就要引入manacher’s算法了,他能够复用我以前比较的结果
manacher’s
- 一开始想这个问题我也试过动态规划的思想,我的想法是利用二位数组dp[i][j] = dp[i+1][j-1] + 2 if str[i] == str[j];利用以前
判断过的回文串来迭代,但是整个算法复杂度还是O(n^2),因为我dp[i][j]无法利用dp[i][j-1]的信息,manacher用了另外一个思路来解决这个问题; - 算法中有几个变量需要定义:
- center,当前最长回文子串的中心坐标index
- right,当前最长回文子串的右边界坐标index
- radius数组,记录字符串每一个位置的最长回文子串半径
- mirror_i,我当前位置处于i,以center为中心,我的对称位置为mirror_i=2*center-i

一句话解释:当我要计算i位置的回文子串时,我会去看mirror_i位置的回文子串长度,因为mirror_i的回文子串会根据center对称
到i位置,所以mirror_i半径以内的字符都是相等的,迭代时会跳过这一部分;这里有一个问题是需要考虑边界right,因为如果mirror_i
的半径超过了mirror_i,我们只能起始点卡在right,因为如果超过right部分是对称的,当前center的半径肯定不是right这个位置,算法
实现如下:
1 | def findPalindromeNum(s:str)->int: |
因为算法实现不是每次都跳到0开始搜索,而是跳到了mirror的radius上开始搜索,可以证明整个算法时间复杂度是O(n)的;
Reference
详解雪花算法
背景
雪花算法解决的问题是,如何在分布式环境下产生一个唯一的id,而这些唯一id在业务或者技术上都会有广泛使用,
比如订单号,一次请求的requestId,traceId等;现有的一些算法比如微软的UUID,他能保证唯一,但是雪花算法
相较于他更有优势的一点,它能保证整体递增,这对我们业务类的id很有用;取名的出处是,世界上找不到两片相同的
雪花,在我们rpc的框架中,也用到了雪花算法来生成request-id;
算法
雪花算法的ID占用64bit,其中分别有不同的含义,第一位bit是符号位,因为我们时间都是正的,所以为0;后续41位为
时间,接着5位datacenterId+5位workerId,最后12bit位sequence表示单机在同一毫秒可以产生的id数量,所以能到单机400w的并发
实现
- 代码实现非常简单,而且单机非常高效
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25//用户自己定义的业务起始值,相当于magic num的概念
private final long twepoch = 1288834974657L;
private long nextId() {
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
LOGGER.error("clock is moving backwards. Rejecting requests until {}.", lastTimestamp);
throw new RuntimeException(
"Clock moved backwards. Refusing to generate id for " + (lastTimestamp - timestamp) +
" milliseconds");
}
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0;
}
lastTimestamp = timestamp;
return ((timestamp - twepoch) << timestampLeftShift) | (datacenterId << datacenterIdShift) |
(workerId << workerIdShift) | sequence;
}总结
雪花算法被广泛的应用,当然工业级别的id生成算法还有很多,包括美团的leaf
百度的UidGenerator
百度使用未来时间,存放到RingBuffer中,再次提升雪花算法的并发度,能到单机600w
Step by Step写一个简易的RPC
背景
在Cloud Native大火的今天,我们想来讲讲在这个体系下比较重要的东西RPC-framework,为什么需要有这个东西呢,需要来讲讲历史了;
最开始代码组织的方式,最原始就是所有code都在一个repo里面,高内聚模式,在业务比较小的时候,这没什么问题!但是到了业务快速发展的时候就会
带来致命的缺陷了:
- 敏捷性
- code全部写在一个repo里面,导致每次开发/测试/上线,编译会花很多时间
- 不同模块间的相互影响,比如模块A需要上线,依赖模块B,模块B由于比较复杂需要很多时间进行测试,导致功能很简单的A迭代速度强依赖于B,无法隔离
- 扩展性
- 不同的模块,承载的业务不同,模块A需要很多机器来承载流量,而模块B却不需要这么多机器,导致很多无用的code跑在机器上占用资源
- 不同模块的SLA要求,不一样,一个999的模块和一个99的模块放在一起显然不合适
- 不同模块的属性不同,有的模块无状态,可以水平扩容,有的模块有状态,无法水平扩容,揉在一起,增加复杂性
现阶段的解决方案是,将一整块的拼图,打碎,划分为,一个个独立的个体,他们相互不影响,各自负责好自己的事情即可,引出来的架构叫SOA(Service-Oriented Architecture),
里面很重要的一个能力就是支持,服务间调用,走远端的模式就是RPC,下面讲讲,常见RPC的架构体系
INFRA
大部分的RPC主要分为三个部分,客户端,服务端,注册中心
- 客户端
- 客户端主要是服务的调用方,他有几种operation:1.从注册中心拉去配置 2.和服务端建立连接 3.向服务端发起request
- 注册中心
- 注册中心主要用来保存服务的元数据,比如1.现在有多少个service 2.每个service的provider有哪些 3.检测存活的provider 4.提供配置信息给客户端
- 服务端
- 服务端是service的提供方,他主要做 1.启动服务并注册到注册中心 2.发送心跳,证明自己还活着 3.提供channel接收用户的request
实现
接下来是干活,整个rpc的实现部分,还是按照客户端,注册中心,服务端来讲,
整个repohttps://github.com/learn2Pro/easyrpc 在此处
- 注册中心
- 注册中心的接口部分,提供一系列meta信息的管理
1
2
3
4
5
6
7
8
9
10
11
12
13public interface RpcConfigServer {
RemoteAddr sense(String service) throws Throwable;
void register(RemoteAddr addr, String service, Class<?> klass);
void unregister(RemoteAddr addr);
default CodecType fetchCodec() {
return CodecType.JSON;
}
}
主要有两种实现
//本地注册中心(测试用)
Class LocalConfigServer extends RpcConfigServer
//Zk注册中心
Class ZkConfigServer extends RpcConfigServer
- 注册中心的接口部分,提供一系列meta信息的管理
- 服务端
- 注册到config server
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public class ProviderRepository implements Repository, ApplicationContextAware, InitializingBean {
...
//寻找provider注解,并注册到注册中心
private void registerProvider(ApplicationContext app) {
for (Map.Entry<String, Object> entry : app.getBeansWithAnnotation(Provider.class).entrySet()) {
Class<?> klass = entry.getValue().getClass();
Provider ann = klass.getAnnotation(Provider.class);
String name =
StringUtils.isEmpty(ann.value()) ? StringUtils.uncapitalize(klass.getSimpleName())
: ann.value();
rpcConfigServer.register(RemoteAddr.local(), name, klass);
}
}
...
} - 启动socket端口监听请求,使用netty-io
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
public class ProviderRouter implements InitializingBean {
/**
* logger instance
*/
private static final Logger LOGGER = LoggerFactory.getLogger(ProviderRouter.class);
private RpcProviderHandler rpcProviderHandler;
private CodecEncodeHandler codecEncodeHandler;
private RpcConfigServer rpcConfigServer;
private EventLoopGroup master;
private EventLoopGroup workers;
/**
* start server for rpc provider
*
* @throws Exception init failed
*/
public void afterPropertiesSet() throws Exception {
master = new NioEventLoopGroup(1);
workers = new NioEventLoopGroup(10);
RemoteAddr addr = RemoteAddr.local();
new Thread(() -> {
try {
ServerBootstrap server = new ServerBootstrap();
server.group(master, workers)
.channel(NioServerSocketChannel.class)
.localAddress(new InetSocketAddress(Integer.parseInt(addr.getPort())))
.childHandler(new ChannelInitializer<SocketChannel>() {
protected void initChannel(SocketChannel ch) throws Exception {
ch.pipeline()
.addLast("prepend", new LengthFieldPrepender(2))
.addLast("remove", new LengthFieldBasedFrameDecoder(65536, 0, 2, 0, 2))
.addLast("decoder", new CodecDecodeHandler(rpcConfigServer.fetchCodec(),
RpcRequest.class))
.addLast("encoder", codecEncodeHandler)
.addLast("rpc_provider", rpcProviderHandler);
}
});
ChannelFuture channelFuture = server.bind().sync();
LOGGER.info(RpcProviderHandler.class.getName() +
" started and listening for connections on " + channelFuture.channel().localAddress());
channelFuture.channel().closeFuture().sync();
} catch (Exception e) {
master.shutdownGracefully();
workers.shutdownGracefully();
}
}).start();
}
public void destroy() throws InterruptedException {
LOGGER.info("server shutdown going...");
master.shutdownGracefully().sync();
workers.shutdownGracefully().sync();
}
}
- 注册到config server
- 消费端
- 判断是call走近端还是远端,创建对应的proxy,整个过程是且契合到spring的lifecycle中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68public class ConsumerBeanPostProcessor implements BeanPostProcessor,
ApplicationContextAware {
/**
* the app instance
*/
private ApplicationContext app;
/**
* remote rpc services
*/
private Set<String> remoteServices = Sets.newHashSet();
/**
* register consumer for class
*
* @param targetName the instance name
* @param inner the inner class
* @return
*/
private Object createProxy(String targetName, Class<?> inner, ProviderType typo) {
if (this.app.containsBean(targetName) && typo == ProviderType.LOCAL) {
return Proxy
.newProxyInstance(Thread.currentThread().getContextClassLoader(), new Class[]{inner},
new LocalInvocationWrapper(targetName, inner));
} else {
return Proxy
.newProxyInstance(Thread.currentThread().getContextClassLoader(), new Class[]{inner},
new RemoteInvocationWrapper(targetName, inner));
}
}
public Object postProcessBeforeInitialization(Object bean, String beanName)
throws BeansException {
Class<?> target = bean.getClass();
for (Field field : target.getDeclaredFields()) {
//inject consumer
if (field.getAnnotation(Consumer.class) != null && field.getType().isInterface()) {
Consumer ann = field.getAnnotation(Consumer.class);
String name = ann.value();
String targetName =
StringUtils.isEmpty(name) ? StringUtils.uncapitalize(field.getType().getSimpleName())
: name;
if (ann.typo() == ProviderType.REMOTE || !this.app.containsBean(targetName)) {
remoteServices.add(targetName);
}
Object instance = this.createProxy(targetName, field.getType(), ann.typo());
field.setAccessible(true);
ReflectionUtils.setField(field, bean, instance);
}
}
return bean;
}
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.app = applicationContext;
}
/**
* get all remote services
*
* @return service set
*/
public Set<String> getRemoteServices() {
return remoteServices;
}
}- 请求处理,此处使用了生产者消费者模型,通过队列的方式异步化,增加吞吐量,可以基于此做到控速和反压(backpush)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193public interface RpcMsgPool {
ExecutorService PROCESSORS = new ThreadPoolExecutor(5, 5, 0,
TimeUnit.MICROSECONDS, new LinkedBlockingDeque<>(500));
void answer(RpcResponse response);
Future<RpcResponse> send(RpcRequest request);
}
public class AsyncRpcMsgPool implements RpcMsgPool, InitializingBean, DisposableBean {
private static final AsyncRpcMsgPool INSTANCE = new AsyncRpcMsgPool();
private static final BlockingQueue<RpcRequest> REQUEST_QUEUE = new LinkedBlockingQueue<>(
10000);
protected static final Map<String, RpcRequest> REQUEST_MAP = Maps.newConcurrentMap();
protected static final Map<String, RpcResponse> RESPONSE_POOL = Maps
.newConcurrentMap();
private static final Logger LOGGER = LoggerFactory.getLogger(AsyncRpcMsgPool.class);
/**
* Lock held by take, poll, etc
*/
private final ReentrantLock takeLock = new ReentrantLock();
/**
* Wait queue for waiting takes
*/
private final Condition updated = takeLock.newCondition();
private volatile boolean stop = false;
private ConsumerRouter consumerRouter;
public static AsyncRpcMsgPool getInstance() {
return INSTANCE;
}
private RpcResponse fetch(String requestId) throws InterruptedException {
takeLock.lockInterruptibly();
try {
while (!RESPONSE_POOL.containsKey(requestId)) {
updated.await();
}
RpcResponse response = RESPONSE_POOL.get(requestId);
RESPONSE_POOL.remove(requestId);
return response;
} finally {
takeLock.unlock();
}
}
/**
* fetch the specified response of request id
*
* @param requestId the request id
* @return the response
*/
private RpcResponse fetch(String requestId, long timeout)
throws InterruptedException, TimeoutException {
takeLock.lockInterruptibly();
try {
while (!RESPONSE_POOL.containsKey(requestId)) {
if (!updated.await(timeout, TimeUnit.MILLISECONDS)) {
throw new TimeoutException("fetch result timeout!");
}
}
RpcResponse response = RESPONSE_POOL.get(requestId);
RESPONSE_POOL.remove(requestId);
REQUEST_MAP.remove(requestId);
return response;
} finally {
takeLock.unlock();
}
}
/**
* send requst to server
*
* @param request the request info
* @return the future of response
*/
public Future<RpcResponse> send(RpcRequest request) {
REQUEST_QUEUE.add(request);
REQUEST_MAP.put(request.getSessionId(), request);
return new RpcFuture(request.getSessionId());
}
public void answer(RpcResponse response) {
RESPONSE_POOL.put(response.getId(), response);
signalNotEmpty();
}
public RpcRequest search(String sessionId) {
return REQUEST_MAP.get(sessionId);
}
/**
* Signals a waiting take. Called only from put/offer (which do not otherwise ordinarily lock
* takeLock.)
*/
private void signalNotEmpty() {
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
updated.signalAll();
} finally {
takeLock.unlock();
}
}
("unchecked")
public void afterPropertiesSet() throws Exception {
PROCESSORS.execute(() -> {
try {
for (; ; ) {
if (stop) {
return;
}
RpcRequest request = REQUEST_QUEUE.take();
consumerRouter.choose(request.getServiceId()).writeAndFlush(request);
}
} catch (InterruptedException e) {
LOGGER.error("this request fetch failed!", e);
}
});
}
public void destroy() throws Exception {
stop = true;
}
static final class RpcFuture implements Future<RpcResponse> {
/**
* the request id
*/
private String requestId;
public RpcFuture(String requestId) {
this.requestId = requestId;
}
public boolean cancel(boolean mayInterruptIfRunning) {
return true;
}
public boolean isCancelled() {
return true;
}
public boolean isDone() {
return AsyncRpcMsgPool.RESPONSE_POOL.containsKey(requestId);
}
public RpcResponse get() throws InterruptedException {
return getInstance().fetch(requestId);
}
public RpcResponse get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException {
long to = 0;
switch (unit) {
case DAYS:
to = TimeUnit.DAYS.toMillis(timeout);
break;
case HOURS:
to = TimeUnit.HOURS.toMillis(timeout);
break;
case MINUTES:
to = TimeUnit.MINUTES.toMillis(timeout);
break;
case SECONDS:
to = TimeUnit.SECONDS.toMillis(timeout);
break;
case MILLISECONDS:
to = TimeUnit.MILLISECONDS.toMillis(timeout);
break;
case MICROSECONDS:
to = TimeUnit.MICROSECONDS.toMillis(timeout);
break;
case NANOSECONDS:
to = TimeUnit.NANOSECONDS.toMillis(timeout);
break;
}
return getInstance().fetch(requestId, to);
}
}
}
- 请求处理,此处使用了生产者消费者模型,通过队列的方式异步化,增加吞吐量,可以基于此做到控速和反压(backpush)
- 判断是call走近端还是远端,创建对应的proxy,整个过程是且契合到spring的lifecycle中
- 工具类
- encoding工具,实现了json和pb的序列化,因为网络传输的都是bytes
1
2
3
4
5
6public interface CodecProcessor<T extends RpcSerModel> {
byte[] encode(T data);
T decode(byte[] bytes);
}
class JSONCodecProcessor extends CodecProcessor;
class ProtoCodecProcessor extends CodecProcessor; - id生号器,每个请求会有唯一的标识,我们通过的是生号器去解决这个问题,uuid和snowflake两种算法
1
2
3
4
5public interface Generator {
String generateId();
}
class UUIDGenerator extends Generator;
class SnowflakeGenerator extends Generator;总结
通过上面一系列的工作,我们的简易RPC框架就完成了,实践是学习很好的途径,每个人在做的过程中,会提出不同的问题,有不同的创新;
分享出来是很好的成长!
- encoding工具,实现了json和pb的序列化,因为网络传输的都是bytes
HEXO+GITHUB搭建个人博客
在github上搭建博客一般使用Jekyll static blogs的方式,非常方便快捷,但是有个缺点便是切换theme很不方便;用Jekyll相对普通人来说已经足够,但是如果需要强大的模版,一些可扩展的东西,就会比较麻烦,需要对前端有一定的技术背景。
所以出现了
Hexo :+1:
1
What is Hexo?Hexo is a fast, simple and powerful blog framework. You write posts in Markdown (or other languages) and Hexo generates static files with a beautiful theme in seconds.
Hexo = Node.js + MarkDown
Hexo切换模板非常方便只需要修改配置文件重新generate一下,Hexo官方文档Document
安装Hexo之前需要安装node和git:- Node.js
- Git
如果你的电脑已经安装好了node和git,使用npm安装:
1 | $ npm install -g hexo-cli |
然后去挑选喜欢hexo模板themes开始搭建个人博客了,或者github上面搜索hexo themes有很多高star的模板,本文的博客
采用的是litten,非常感谢;
1 | $ mkdir <foldser> |
深度学习-机器学习经典算法
机器学习的算法主要包含监督学习和非监督学习两个大类:
监督学习:简单的说便是,样本集带有属性,需要根据样本集判断新的采样点的属性,常见的knn,svm
非监督学习:与监督学习相反,样本集没有属性信息,需要划分出样本集的分类,常见k-means;
K-means
k-means,k代表将要聚类出的k个cluster,算法流程:
1.随机选出样本集N中k个采样点作为cluster的中心;
2.样板集N中其他采样点选取离自己距离最近的k个cluster center点作为自己的中心点然后
3.通过2我们获得了k个cluster,每个cluster里面有很多点,通过这些点算出每个cluster的中心点(离中心最近的点)
4.重复2,3 直到结果收敛
5.在此算法中比较重要的是距离的计算,根据不同场景使用不同的方式,常用几种距离:
欧几里得距离(Euclidean Distance)
欧氏距离是最常见的距离度量,衡量的是多维空间中各个点之间的绝对距离。公式如下: