在上一次的文章bird学习路径的迭代原理便是CNN网络,本文将介绍Flabby-bird的整个实现算法
概述

卷积神经网络(Convolutional Neural Network, CNN)是深度学习技术中极具代表的网络结构之一,在图像处理领域取得了很大的成功,在国际标准的ImageNet数据集上,许多成功的模型都是基于CNN的。CNN相较于传统的图像处理算法的优点之一在于,避免了对图像复杂的前期预处理过程(提取人工特征等),可以直接输入原始图像。
图像处理中,往往会将图像看成是一个或多个的二维向量,如之前博文中提到的MNIST手写体图片就可以看做是一个28 × 28的二维向量(黑白图片,只有一个颜色通道;如果是RGB表示的彩色图片则有三个颜色通道,可表示为三张二维向量)。传统的神经网络都是采用全连接的方式,即输入层到隐藏层的神经元都是全部连接的,这样做将导致参数量巨大,使得网络训练耗时甚至难以训练,而CNN则通过局部连接、权值共享等方法避免这一困难,有趣的是,这些方法都是受到现代生物神经网络相关研究的启发(感兴趣可阅读以下部分)。
下面重点介绍下CNN中的局部连接(Sparse Connectivity)和权值共享(Shared Weights)方法,理解它们很重要。
局部连接与权值共享
下图是一个很经典的图示,左边是全连接,右边是局部连接。
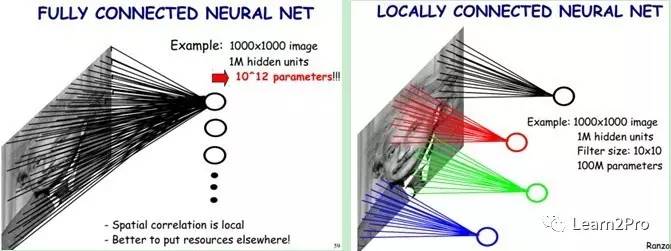
对于一个1000 × 1000的输入图像而言,如果下一个隐藏层的神经元数目为10^6个,采用全连接则有1000 × 1000 × 10^6 = 10^12个权值参数,如此数目巨大的参数几乎难以训练;而采用局部连接,隐藏层的每个神经元仅与图像中10 × 10的局部图像相连接,那么此时的权值参数数量为10 × 10 × 10^6 = 10^8,将直接减少4个数量级。
尽管减少了几个数量级,但参数数量依然较多。能不能再进一步减少呢?能!方法就是权值共享。具体做法是,在局部连接中隐藏层的每一个神经元连接的是一个10 × 10的局部图像,因此有10 × 10个权值参数,将这10 × 10个权值参数共享给剩下的神经元,也就是说隐藏层中10^6个神经元的权值参数相同,那么此时不管隐藏层神经元的数目是多少,需要训练的参数就是这 10 × 10个权值参数(也就是卷积核(也称滤波器)的大小),如下图。
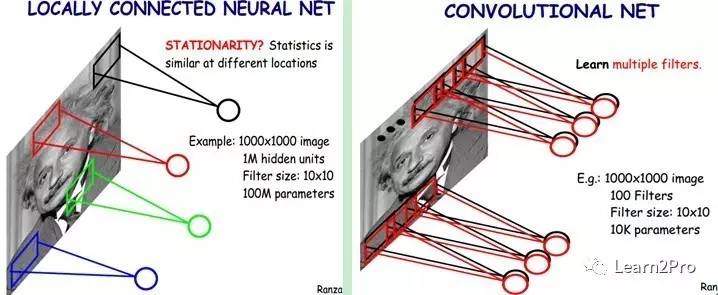
这大概就是CNN的一个神奇之处,尽管只有这么少的参数,依旧有出色的性能。但是,这样仅提取了图像的一种特征,如果要多提取出一些特征,可以增加多个卷积核,不同的卷积核能够得到图像的不同映射下的特征,称之为Feature Map。如果有100个卷积核,最终的权值参数也仅为100 × 100 = 10^4个而已。另外,偏置参数也是共享的,同一种滤波器共享一个。
卷积神经网络的核心思想是:局部感受野(local field),权值共享以及时间或空间亚采样这三种思想结合起来,获得了某种程度的位移、尺度、形变不变性(?不够理解透彻?)。
网络结构
下图是一个经典的CNN结构,称为LeNet-5网络。
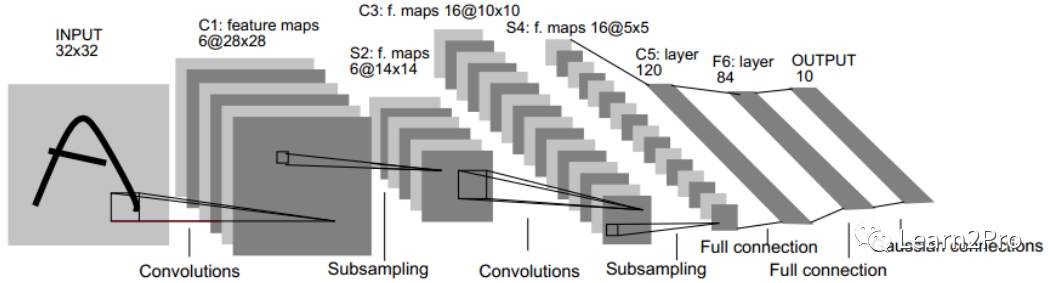
可以看出,CNN中主要有两种类型的网络层,分别是卷积层和池化/采样层(Pooling)。卷积层的作用是提取图像的各种特征;池化层的作用是对原始特征信号进行抽象,从而大幅度减少训练参数,另外还可以减轻模型过拟合的程度。
卷积层
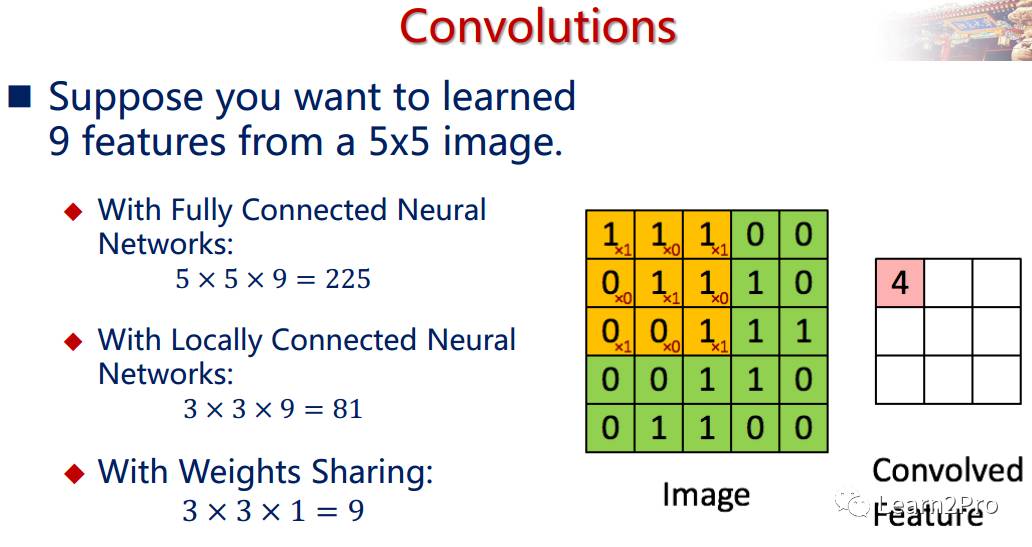
卷积层是卷积核在上一级输入层上通过逐一滑动窗口计算而得,卷积核中的每一个参数都相当于传统神经网络中的权值参数,与对应的局部像素相连接,将卷积核的各个参数与对应的局部像素值相乘之和,(通常还要再加上一个偏置参数),得到卷积层上的结果。如下图所示。
下面的动图能够更好地解释卷积过程:
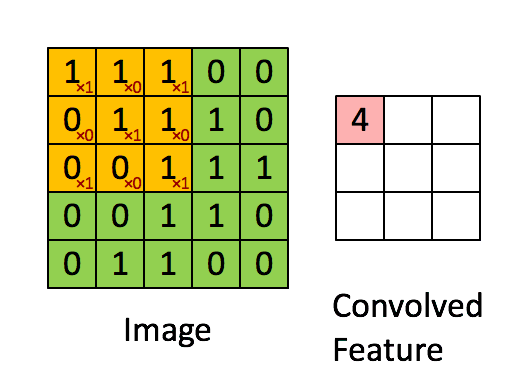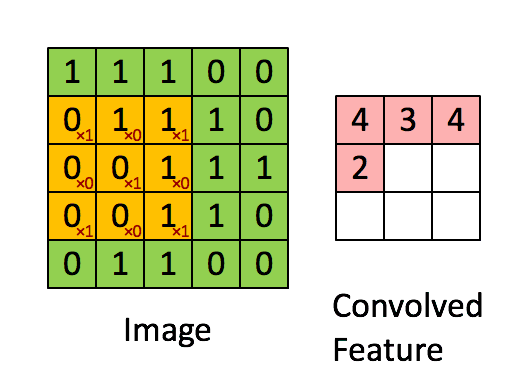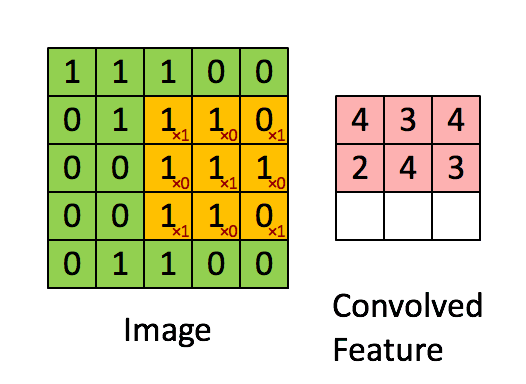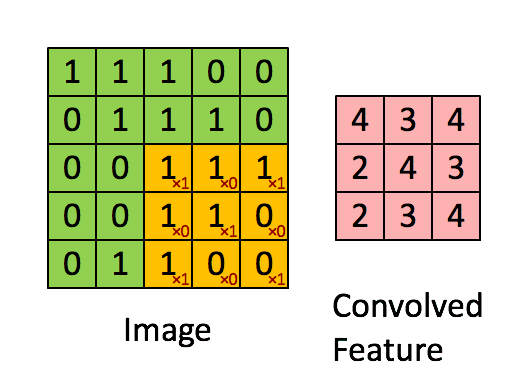
池化/采样层
通过卷积层获得了图像的特征之后,理论上我们可以直接使用这些特征训练分类器(如softmax),但是这样做将面临巨大的计算量的挑战,而且容易产生过拟合的现象。为了进一步降低网络训练参数及模型的过拟合程度,我们对卷积层进行池化/采样(Pooling)处理。池化/采样的方式通常有以下两种:
Max-Pooling: 选择Pooling窗口中的最大值作为采样值;
Mean-Pooling: 将Pooling窗口中的所有值相加取平均,以平均值作为采样值;如下图所示。

LeNet-5网络详解
以上较详细地介绍了CNN的网络结构和基本原理,下面介绍一个经典的CNN模型:LeNet-5网络。
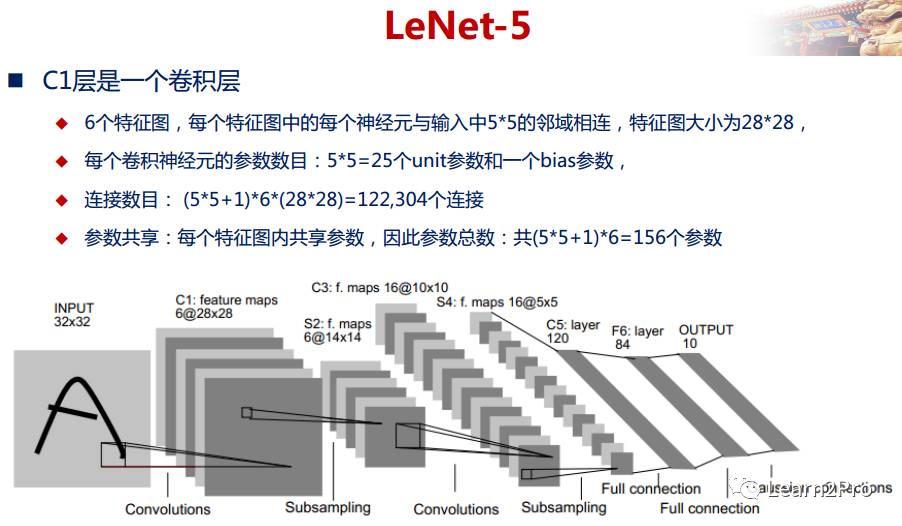
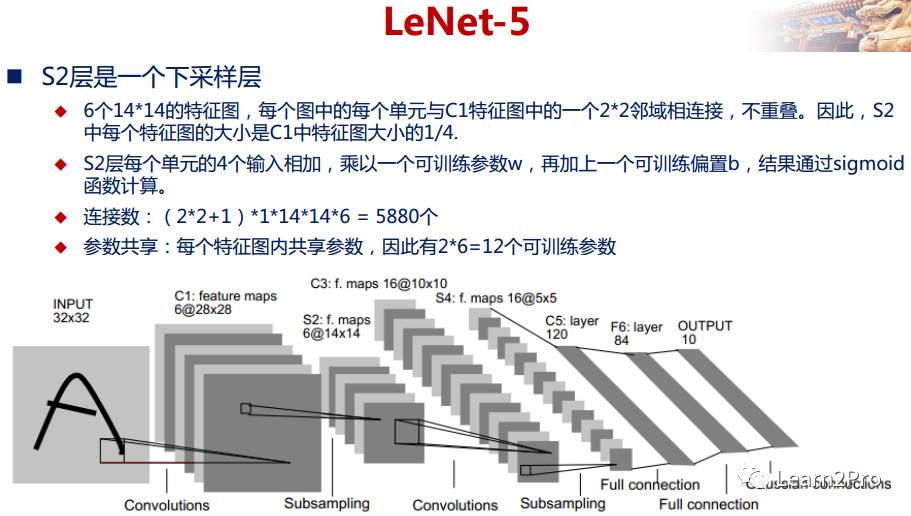
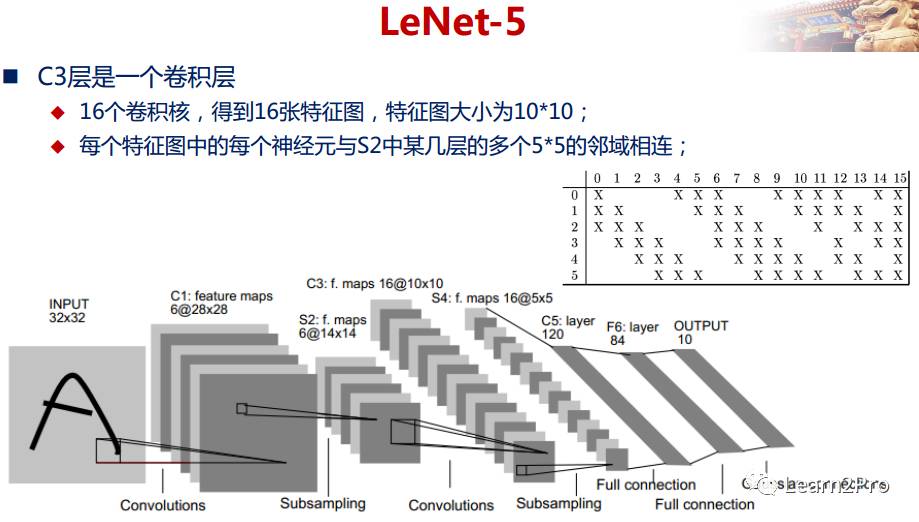
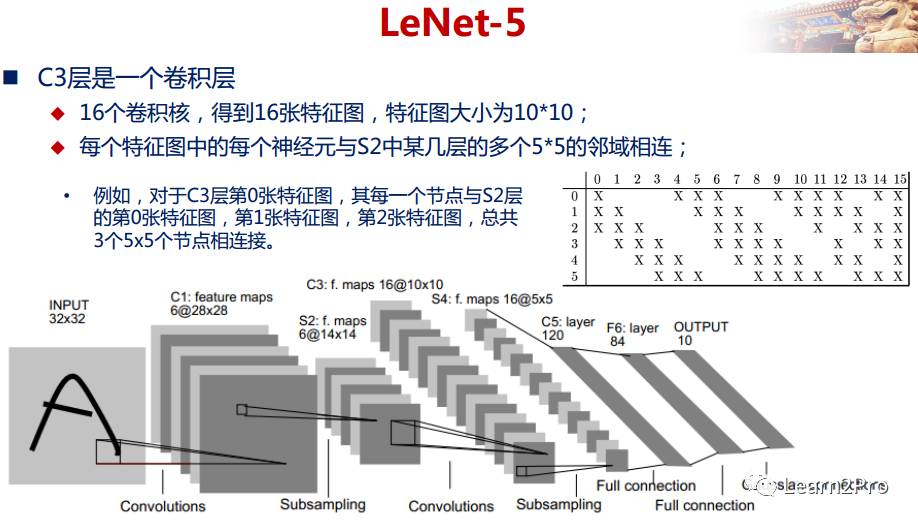
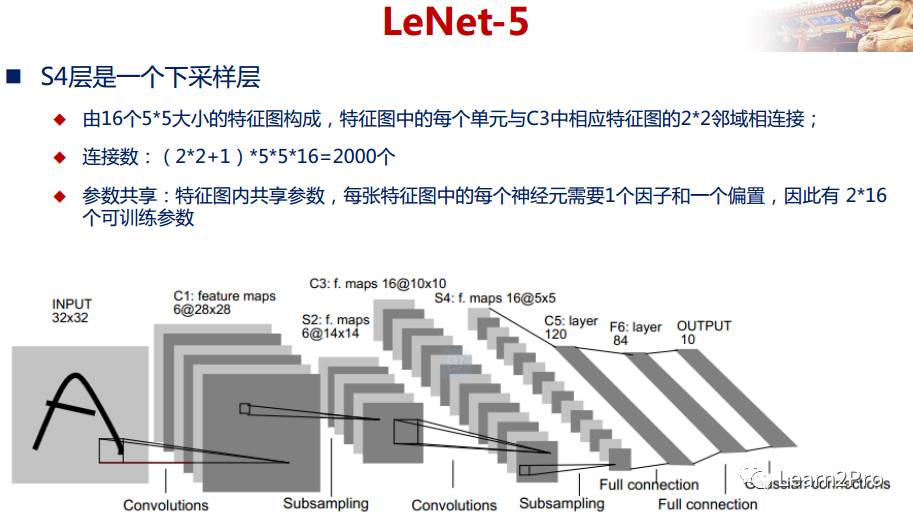
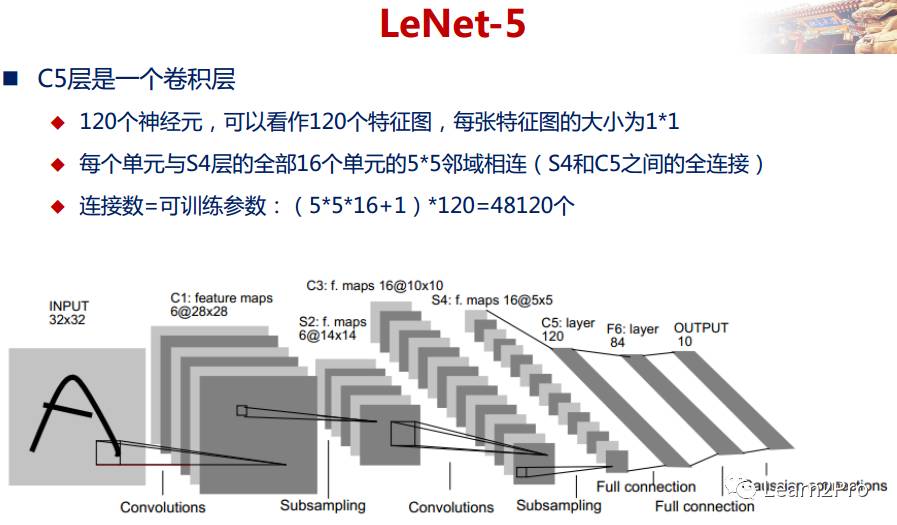
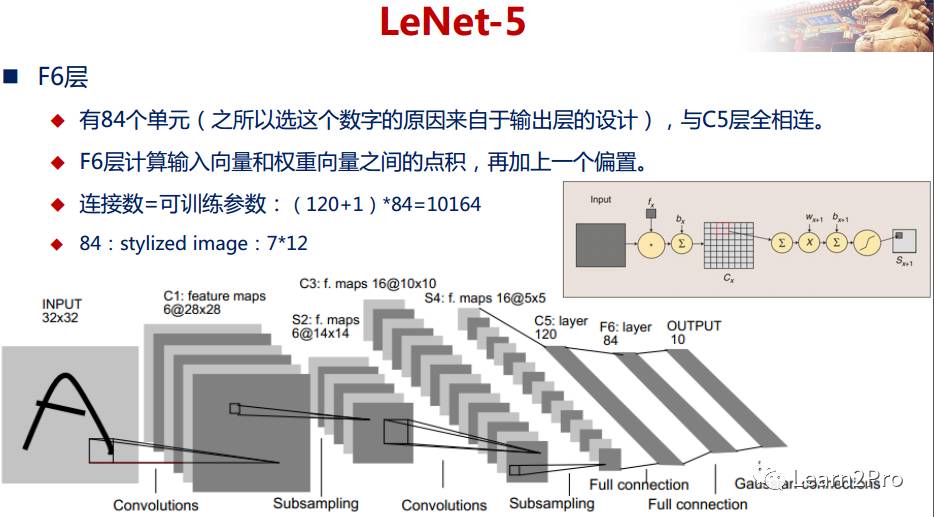
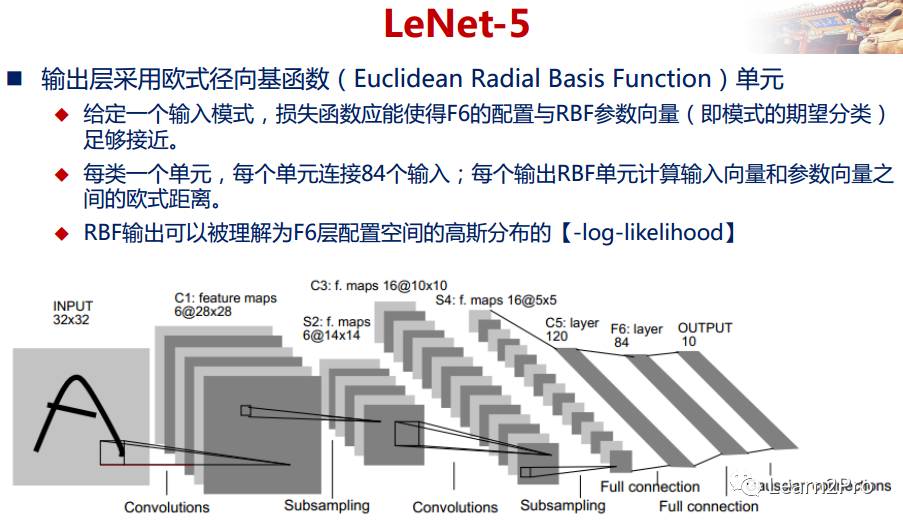
LeNet-5网络在MNIST数据集上的结果

Flabby-bird整个的学习过程如下:
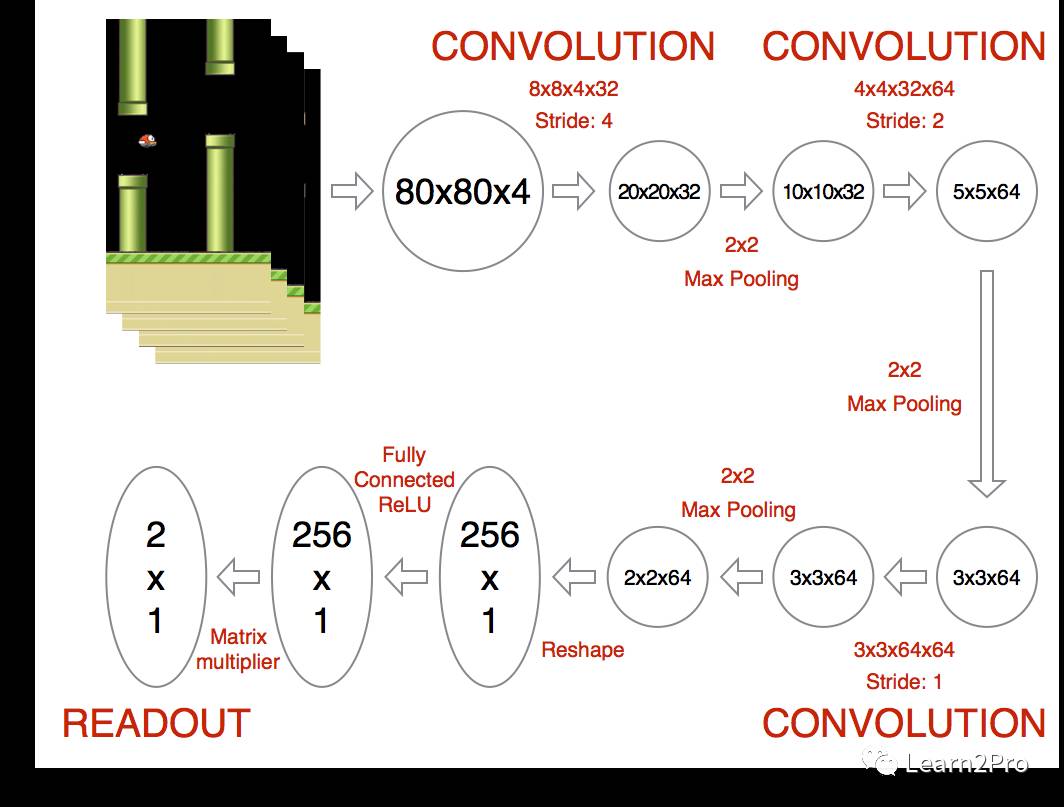
代码如下:
Initialize replay memory D to size N
Initialize action-value function Q with random weights
for episode = 1, M do
Initialize state s_1
for t = 1, T do
With probability ϵ select random action a_t
otherwise select a_t=max_a Q(s_t,a; θi)
Execute action a_t in emulator and observe r_t and s(t+1)
Store transition (s_t,a_t,r_t,s_(t+1)) in D
Sample a minibatch of transitions (s_j,a_j,r_j,s_(j+1)) from D
Set y_j:=
r_j for terminal s_(j+1)
r_j+γ*max_(a^’ ) Q(s_(j+1),a’; θi) for non-terminal s(j+1)
Perform a gradient step on (y_j-Q(s_j,a_j; θ_i))^2 with respect to θ
end for
end for